
We all know the pattern when an incident hits. It starts with a spike in latency, then Slack channels begin to flood with alerts. A major AWS region is degrading, or Cloudflare is re-routing traffic globally.
For most tech teams, the immediate panic is focused on uptime: Is the app responsive? Can users log in?
Hours later, the status pages flip from red to green. The incident is marked “resolved”. The DevOps team signs off.
But for Data Engineers, the real work is just beginning. While the web application is back online, the data ecosystem is deep in what we call a “data hangover”, the delayed and painful aftermath of an outage that doesn't show up on any status page. The pipes are running again, but what's flowing through them is incomplete, duplicated, or out of sync.
This article breaks down the data integrity risks that follow a cloud outage, and the architectural patterns we implement at Lenstra to make sure our pipelines survive them.
What are the risks associated with a data crash?
The problem is that most modern data pipelines are built like Just-In-Time (JIT) supply chains. They assume data will arrive exactly when needed. But when the cloud crashes, the delivery mechanism stops, and the backlog begins to pile up.
When the service finally restarts, you don't return to normal operations immediately. You face a massive surge of data trying to squeeze through the pipe at once. This messy recovery is where integrity breaks down in ways that standard monitoring often misses.
During an incident, there are three data integrity risks that need to be accounted for:
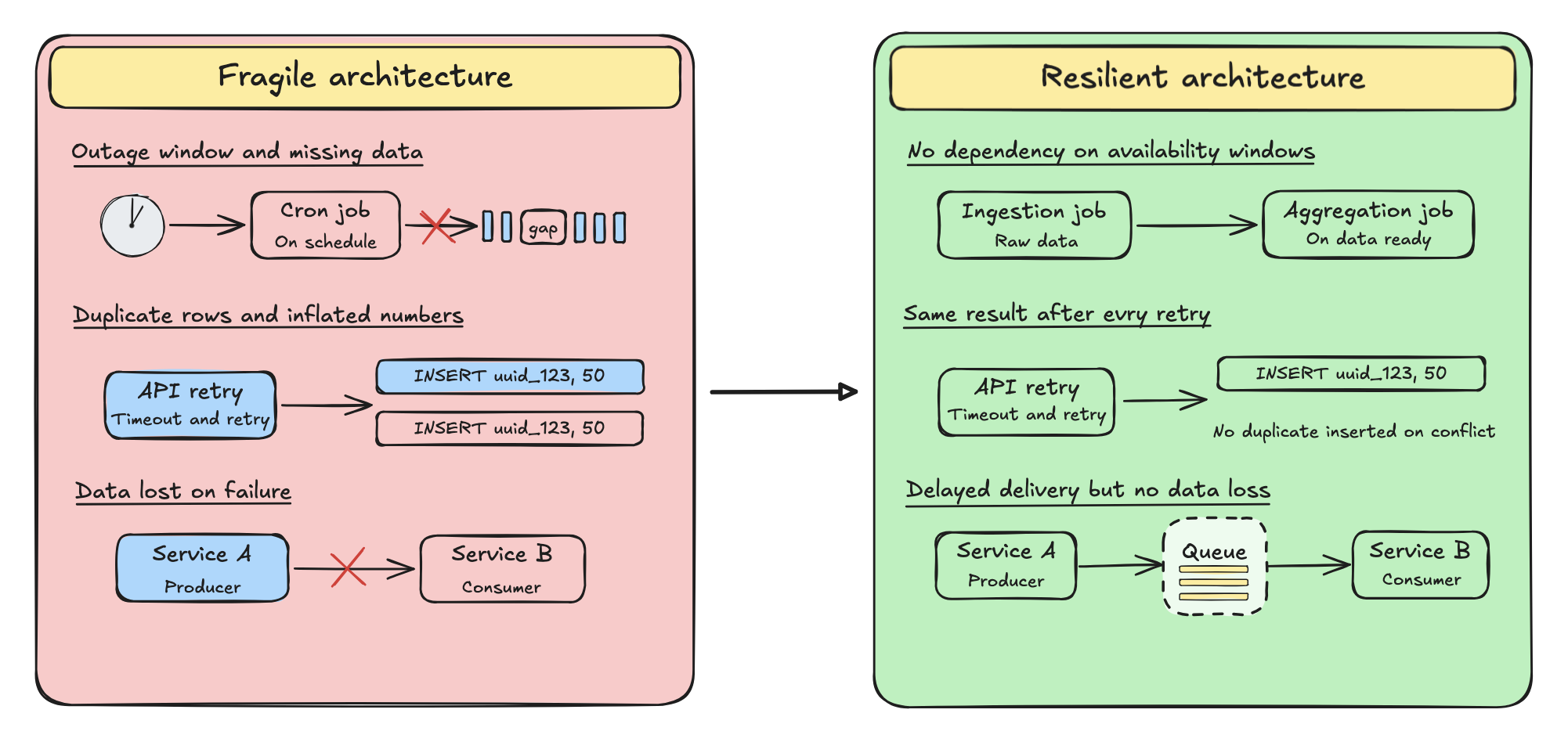
1. Temporal gaps in data pipelines
Cron-based extraction jobs fail to trigger during the downtime. If your logic is simply “fetch the last hour”, the outage window becomes a permanent gap in your historical data.
During the October 2025 AWS us-east-1 outage, a DNS misconfiguration cascaded into failures across AWS solutions, impacting many companies worldwide for several hours. For any team running hourly ingestion jobs during that window, the result was the same: no error, no alert, just missing rows discovered days later during reconciliation.
2. Idempotency failures
First, a quick definition: idempotency is the guarantee that processing the same operation multiple times produces the same result. In data pipelines, it means your system can safely re-process a batch without creating duplicates.
During periods of high latency, upstream APIs often time out and retry automatically. If your ingestion logic lacks strict fingerprinting to identify each record while detecting duplicates, it processes the same transaction twice. Your data now shows inflated numbers that are technically valid rows but factually wrong totals.
This is how a data hangover becomes a trust crisis. When stakeholders look at a dashboard and see metrics that contradict reality caused by a duplicate batch from the outage, they don't file a bug report. They start losing trust in the dashboard, and rebuilding that trust takes time and effort.
3. State desynchronization issues
A write succeeds in the primary database, but the event publisher fails to send the notification to the analytics warehouse. Your production database says “Order confirmed”, but your warehouse has no record of it.
Why is this so hard to catch? Because both systems appear healthy when checked in isolation. After any major outage, dependent services recover at different rates so your transactional database might be back in minutes, while the event bus, CDC pipeline, or warehouse consumer takes hours to drain its backlog. During that gap, the systems drift apart silently. The inconsistency only surfaces when someone runs a cross-system reconciliation, if they run one at all.
Full synchronization guarantees in distributed systems are, by design impossible; as this is a known constraint of distributed computing. That said, the right architectural patterns significantly reduce the blast radius and make these inconsistencies detectable and recoverable. That's what we focus on at Lenstra when designing resilient data architectures for our partners.
Data integrity despite cloud outages
The problem with many modern ETL/ELT architectures is that they rely on synchronous pipelines. They assume a “happy path” where the source API is always up, the transformation layer is always available, and the warehouse is ready to write.
But cloud infrastructure is inherently chaotic. When a single link in this synchronous chain breaks, the entire pipeline fails and often silently.
The most resilient systems aren't the ones that claim 100% uptime, that's impossible. They're the ones that treat data integrity as a non-negotiable guarantee, decoupled from service availability. Their hangover cure isn't manual reconciliation and hope, it's sound architecture.
Resilient architecture checklist
If you want to ensure your data integrity remains intact during the next inevitable failure, your architecture needs to pass these three stress tests.
1. Is our pipeline idempotent?
If the post-outage backlog causes a script to re-process a batch of payments, the system must recognize them as duplicates and not as new entries.
Fragile pattern:
INSERT INTO orders (id, amount) VALUES ('uuid_123', 50);
Resilient pattern:
INSERT INTO orders (id, amount) VALUES ('uuid_123', 50) ON CONFLICT (id) DO NOTHING;
If your disaster recovery plan involves manually running SQL scripts to deduplicate data after every incident, the architecture is already broken.
2. Are we pushing, or are we parking?
In a fragile architecture, service A pushes data synchronously to service B via HTTP. If service B is down, service A errors out and the data is lost.
The fix: Decoupling via asynchronous queues (AWS SQS, Kafka, RabbitMQ,…).
Instead of pushing data directly to the destination, we “park” it in a durable queue. If the warehouse goes down, the data waits safely in the queuing area. When the outage ends, the consumer service comes back online and processes the backlog at its own pace.
What could have been a catastrophic data loss becomes a latency problem instead. The data hangover still happens and the processing runs late, but nothing is lost.
3. Do we run on clock-time or event-time?
Most legacy pipelines are schedule-driven: “Run the aggregation job at 01:00 AM”.
But if the infrastructure is down at 01:00 AM, the job simply fails. By the time the server recovers at 08:00 AM, the window has passed and the scheduler moves on.
Event-driven architectures flip this model. Instead of “Run at 01:00 AM”, the logic becomes: “Run immediately after the raw data batch is successfully handled”.
If the system goes down, the events stack up and wait to be consumed. When it comes back on, the chain picks up where it stopped. The data hangover means things arrive late but they arrive complete and accurate.
Conclusion
Cloud outages are inevitable and service recovery is visible, celebrated and tracked on status pages. Data recovery is none of those things. It's silent, manual, and often discovered only when a report doesn't add up weeks later.
The teams that come out of an outage with their data intact aren't lucky, they built systems that treat integrity as a guarantee and designed their pipelines to expect failure.
If your last incident left you unsure whether your data came out whole, or if you want to make sure the next one doesn't, then your team needs to own data integrity as an engineering metric. That’s part of what we specialize in at Lenstra: bringing structure to data systems and anticipating risks before they turn into incidents. Let’s talk.









