
Nous connaissons tous le scénario lorsqu’un incident survient. Tout commence par un pic de latence, puis les canaux Slack sont inondés d’alertes. Une région AWS majeure se dégrade, ou Cloudflare redirige le trafic à l’échelle mondiale.
Pour la plupart des équipes techniques, la panique initiale se concentre sur la disponibilité : l’application répond-elle ? Les utilisateurs peuvent-ils se connecter ?
Quelques heures plus tard, les pages de statut repassent du rouge au vert. L’incident est marqué comme “résolu”. L’équipe DevOps valide la remise en service.
Mais pour les Data Engineers, le vrai travail ne fait que commencer. Même si l’application web est de nouveau en ligne, l’écosystème data est plongé dans ce que l’on peut appeler une “Data hangover” les conséquences retardées et douloureuses d’une panne qui n’apparaît sur aucune page de statut. Les tuyaux fonctionnent à nouveau, mais ce qui y circule est incomplet, dupliqué ou désynchronisé.
Cet article détaille les risques sur l’intégrité des données qui apparaissent après une panne Cloud, ainsi que les patterns d’architecture que nous mettons en œuvre chez Lenstra pour garantir que nos pipelines y résistent.
Quels sont les risques pour vos data pipelines lors d'un crash cloud
Le problème, c’est que la plupart des data pipelines modernes sont construits comme des chaînes d’approvisionnement en Just-In-Time (JIT) supply chains. Ils partent du principe que la donnée arrivera exactement au moment où elle est nécessaire. Mais lorsqu’un cloud tombe en panne, le mécanisme de livraison s’arrête, et les données en attente commencent à s’accumuler.
Quand le service redémarre enfin, on ne revient pas immédiatement à un fonctionnement normal. On fait face à un afflux massif de données qui tente de repasser dans le pipeline en même temps. Cette phase de reprise chaotique est précisément celle où l’intégrité se dégrade, de manière souvent invisible pour les systèmes de monitoring standards.
Lors d’un incident, il existe trois risques majeurs liés à l’intégrité des données qui doivent être pris en compte :
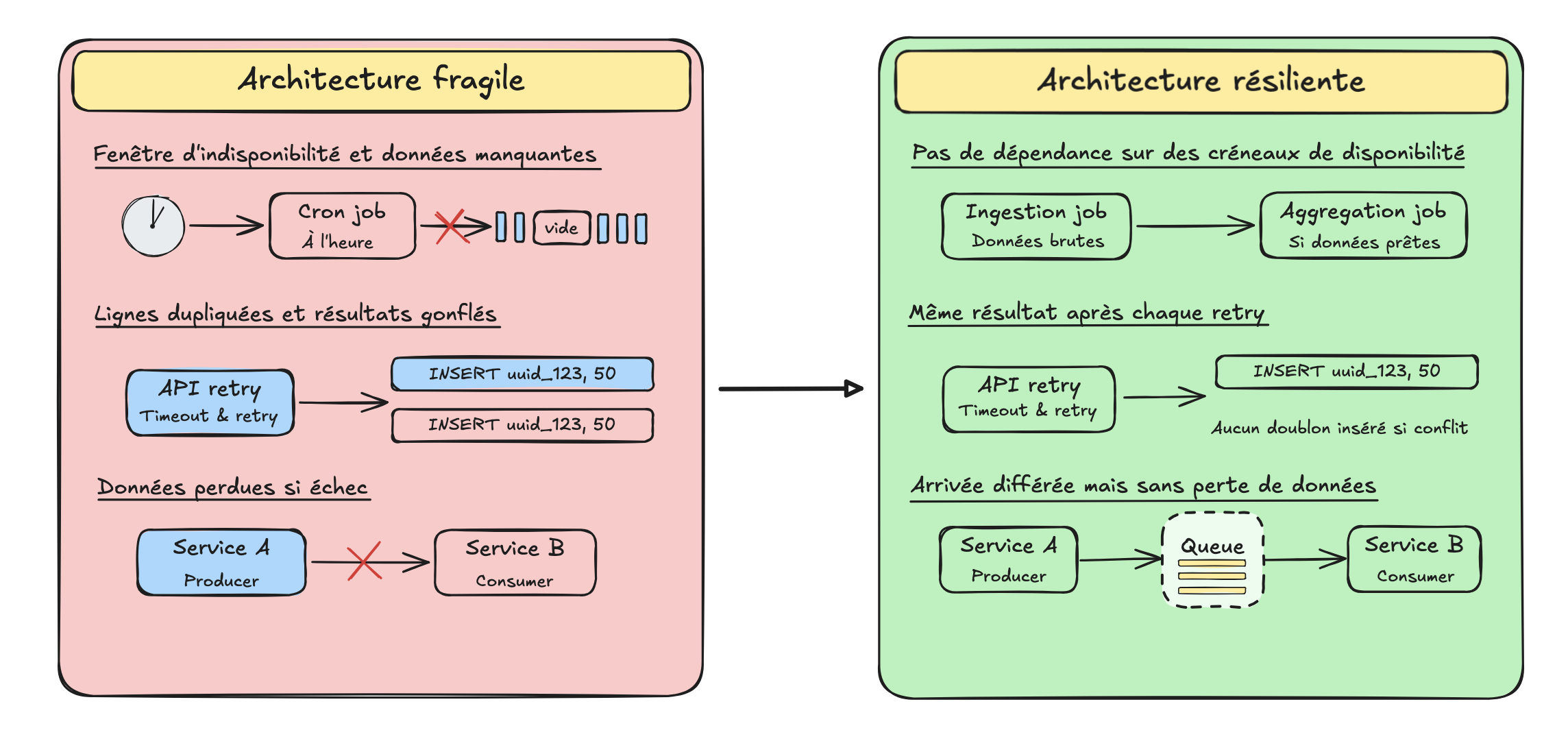
1. Des fenêtres temporelles manquantes dans les data pipelines
Les jobs d’extraction Cron-based ne se déclenchent pas pendant la période de panne. Si votre logique se limite à “récupérer la dernière heure”, la fenêtre d’incident devient alors une perte permanente dans l’historique des données.
Lors de la panne AWS us-east-1 d’octobre 2025, une mauvaise configuration DNS a provoqué une cascade de défaillances sur l’ensemble des services AWS, impactant de nombreuses entreprises dans le monde pendant plusieurs heures. Pour toute équipe exécutant des jobs d’ingestion horaires sur cette période, le constat est le même : aucune erreur, aucune alerte, seulement des lignes manquantes découvertes plusieurs jours plus tard lors des opérations de réconciliation.
2. Problèmes d’idempotence
Tout d’abord, une définition rapide : l’idempotence est la garantie que le fait de traiter plusieurs fois la même opération produit le même résultat. Dans les pipelines data, cela signifie que votre système peut retraiter un batch sans créer de doublons.
Pendant les périodes de forte latence, les APIs en amont expirent souvent et déclenchent des retry automatiques. Si votre logique d’ingestion ne repose pas sur un fingerprinting strict permettant d’identifier chaque ajout tout en détectant les doublons, elle peut traiter deux fois la même transaction. Vos données affichent alors des chiffres gonflés, qui correspondent à des lignes techniquement valides mais à des totaux factuellement faux.
C’est ainsi qu’un “data hangover” devient une crise de confiance. Lorsque les parties prenantes consultent un dashboard et voient des métriques qui contredisent la réalité à cause d’un batch dupliqué lors de l’incident, elles ne remontent pas un bug. Elles commencent à perdre confiance dans le dashboard, et reconstruire cette confiance demande du temps et des efforts.
3. Problèmes de désynchronisation d’état
Une écriture est validée dans la base de données principale, mais le système de publication d’événements échoue à envoyer la notification vers l’entrepôt analytics. Votre base de production indique “Commande confirmée” , mais votre entrepôt de données ne contient aucune trace de cette commande.
Pourquoi est-ce si difficile à détecter ? Parce que les deux systèmes semblent fonctionner correctement lorsqu’ils sont observés séparément. Après une panne majeure, les services qui se dépendent entre eux ne récupèrent pas tous au même rythme : la base transactionnelle peut redevenir opérationnelle en quelques minutes, tandis que le bus d’événements, le pipeline CDC ou le consumer de l’entrepôt peuvent mettre des heures à résorber leur backlog. Pendant cet intervalle, les systèmes dérivent silencieusement. L’incohérence n’apparaît que lorsqu’une réconciliation entre systèmes est effectuée si elle est effectuée.
Les garanties de synchronisation totale dans les systèmes distribués sont, par conception, impossibles ; il s’agit d’une contrainte bien connue du calcul distribué. Cela dit, les bons patterns d’architecture permettent de réduire fortement le rayon d’impact et de rendre ces incohérences détectables et récupérables. C’est précisément ce sur quoi nous nous concentrons chez Lenstra lors de la conception d’architectures data résilientes pour nos partenaires.
Intégrité des données malgré les pannes Cloud
Le problème de nombreuses architectures ETL/ELT modernes est qu’elles reposent sur des pipelines synchrones. Elles supposent un “happy path” où l’API source est toujours disponible, la couche de transformation toujours opérationnelle, et l’entrepôt de données toujours prêt à écrire.
Mais l’infrastructure Cloud est par nature chaotique. Lorsqu’un seul maillon de cette chaîne synchrone se brise, l’ensemble du pipeline échoue, et souvent de manière silencieuse.
Les systèmes les plus résilients ne sont pas ceux qui revendiquent 100 % de disponibilité c’est impossible. Ce sont ceux qui traitent l’intégrité des données comme une garantie non négociable, découplée de la disponibilité des services. Leur remède au data hangover n’est pas la réconciliation manuelle et l’espoir, mais une architecture robuste.
Checklist d’architecture data résiliente
Si vous voulez garantir que l’intégrité de vos données reste intacte lors de la prochaine panne inévitable, votre architecture doit réussir ces trois tests de résistance.
1. Votre pipeline est-il idempotent ?
Si le backlog post-incident amène un script à retraiter un batch de paiements, le système doit être capable de les identifier comme des doublons et non comme de nouvelles entrées.
Pattern fragile:
INSERT INTO orders (id, amount) VALUES ('uuid_123', 50);
Pattern résilient:
INSERT INTO orders (id, amount) VALUES ('uuid_123', 50) ON CONFLICT (id) DO NOTHING;
Si votre plan de reprise après sinistre consiste à exécuter manuellement des scripts SQL pour dédupliquer les données après chaque incident, c’est que l’architecture est déjà défaillante.
2. On envoie les données ou on les met en attente ?
Dans une architecture fragile, le service A pousse les données de manière synchrone vers le service B via HTTP. Si le service B est indisponible, le service A échoue et la donnée est perdue.
La solution : le découplage via des files d’attente asynchrones (AWS SQS, Kafka, RabbitMQ, etc.).
Au lieu d’envoyer les données directement vers leur destination, on les “met en attente” dans une file durable. Si l’entrepôt est indisponible, les données restent stockées en sécurité dans la file d’attente. Une fois la panne terminée, le consumer redémarre et traite le backlog à son propre rythme.
Ce qui aurait pu être une perte de données catastrophique devient simplement un problème de latence. Le data hangover est toujours présent et le traitement est retardé, mais rien n’est perdu.
3. Utilise-t-on le temps horaire ou le temps événement ?
La plupart des pipelines legacy sont pilotés par des planifications : “exécuter le job d’agrégation à 01h00”.
Mais si l’infrastructure est en panne à 01h00, le job échoue simplement. Une fois le serveur rétabli à 08h00, la fenêtre est passée et le scheduler continue son cycle.
Les architectures event-driven inversent ce modèle. Au lieu de “exécuter à 01h00”, la logique devient : “exécuter immédiatement après le traitement réussi du batch de données brutes”.
Si le système tombe, les événements s’accumulent et attendent d’être consommés. Lors du redémarrage, la chaîne reprend là où elle s’était arrêtée. Le data hangover signifie que les données arrivent plus tard, mais elles arrivent complètes et exactes.
Conclusion
Les pannes Cloud sont inévitables et la reprise des services est visible, célébrée et suivie sur les pages de monitoring. La récupération des données, elle, n’a rien de tout cela. Elle est silencieuse, manuelle, et souvent découverte uniquement lorsqu’un rapport ne correspond pas plusieurs semaines plus tard.
Les équipes qui sortent d’un incident avec des données intactes ne sont pas chanceuses : elles ont construit des systèmes qui traitent l’intégrité comme une garantie et conçoivent leurs pipelines pour anticiper les défaillances.
Si votre dernier incident vous a laissé dans le doute sur la complétude de vos données, ou si vous voulez vous assurer que le prochain n’aura pas ce problème, alors votre équipe doit considérer l’intégrité des données comme une métrique d’ingénierie à part entière. C’est précisément une partie de ce sur quoi nous travaillons chez Lenstra : apporter de la structure aux systèmes data et anticiper les risques avant qu’ils ne deviennent des incidents. Parlons-en.









