
Pendant deux ans, nous avons accompagné un acteur emblématique du luxe français dans la refonte et la modernisation de son écosystème data. Cet accompagnement s’inscrit dans une démarche globale visant à faire de la donnée un pilier de pilotage et de performance pour l’ensemble des directions de la maison.
De la fiabilisation des flux à la conception d’indicateurs décisionnels, nous avons contribué à bâtir des fondations techniques solides tout en ancrant la donnée au cœur des processus métiers.
Grâce à une expertise alliant compréhension fine des enjeux opérationnels et rigueur technique, nous avons permis à la donnée de devenir un langage commun entre les équipes métiers et techniques: un véritable levier de décision et de transformation pour la maison.
Une maison de luxe française en pleine transformation data
Au cœur du paysage du luxe français, la maison que nous accompagnons incarne l'équilibre entre héritage artisanal et innovation. Présente sur les grands marchés internationaux, elle s’appuie sur des savoir-faire d’exception tout en cherchant à renforcer, grâce à la donnée, la précision et la réactivité de ses décisions.
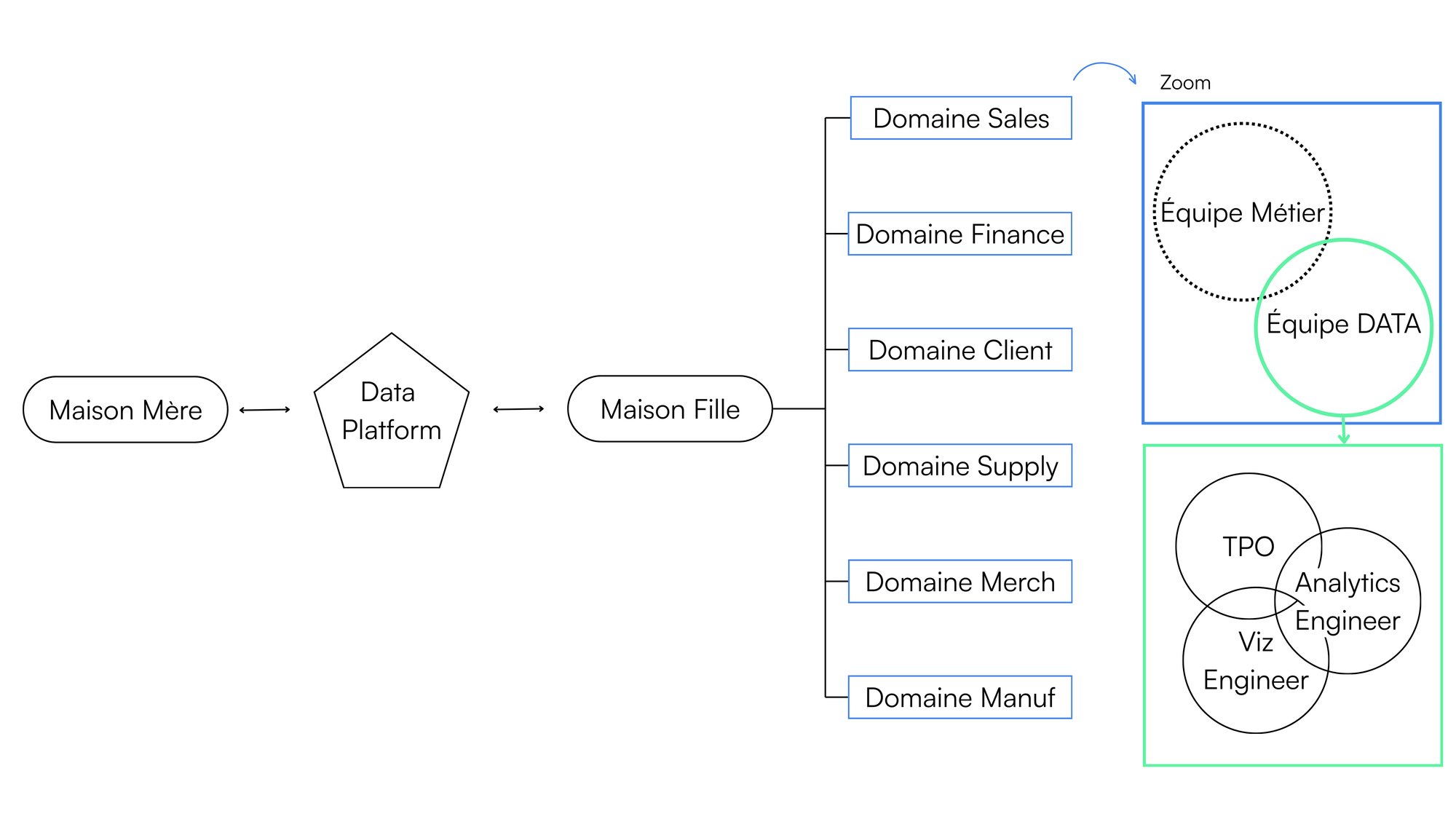
Comme beaucoup d’acteurs du secteur, elle évolue dans un environnement complexe où coexistent plusieurs métiers: retail, e-commerce, digital, finance, supply chain, manufacturing, chacun produisant et consommant des données selon ses propres logiques. Pour soutenir cette transformation, la maison bénéficie d’une Data Platform mutualisée mise à disposition par son groupe international, centralisant les données issues des systèmes clés (ERP, CRM, e-commerce, finance, etc.).
Notre rôle n’était pas seulement d’ingérer la donnée, mais de lui donner sens et valeur : nous souhaitions transformer un actif technique partagé, en un outil de pilotage et d’aide à la décision adapté aux réalités et à la culture métier d’une maison de luxe. Cette mission visait à poser les fondations d’un pilotage data unifié, fiable et durable.
Un data management en structuration
Au lancement du projet, la fonction data de la maison n’avait que deux ans d’existence. Les premiers socles techniques existaient, mais il restait à structurer les pratiques, la gouvernance et les standards pour passer à l’échelle.
Son écosystème reflétait la diversité des métiers : multiplicité de sources, absence de référentiels unifiés, indicateurs calculés différemment selon les équipes, documentation incomplète et architecture éclatée. Autant de signaux témoignant d’une organisation en construction, prête à franchir un nouveau cap.
L’enjeu était donc de bâtir une structure robuste et partagée, permettant à la donnée de devenir un levier collectif de performance et de cohérence.
Quelle structure adopter pour une donnée impactante ?
Notre accompagnement s’est articulé autour de quatre objectifs complémentaires :
- Structurer la gouvernance et les domaines de données afin de créer des référentiels fiables, documentés et partagés par l’ensemble des métiers.
- Développer des produits data adaptés aux usages, en concevant des indicateurs et tableaux de bord alignés sur les processus métier et les besoins décisionnels.
- Moderniser et fiabiliser l’existant, en améliorant les performances, en réduisant les coûts d’exécution et en migrant progressivement vers la Data Platform du groupe.
- Analyser et cartographier l’écosystème data, pour identifier les priorités, les redondances et les opportunités d’amélioration.
Ces piliers ont posé les bases d’une fonction data structurée et durable, où chaque produit technique sert une finalité métier identifiée et claire pour les équipes. La suite de cet article détaille comment cette démarche s’est concrétisée, d’abord dans la collaboration avec les équipes métiers, puis dans l’architecture technique qui soutient la performance et la fiabilité de leurs usages.
Comment co-construire une stratégie data solide en collaborant avec les métiers ?
Comprendre les métiers pour concevoir des produits data utiles
La réussite d’un projet data ne repose pas uniquement sur la technologie, elle dépend aussi et surtout de la compréhension des métiers en amont. Dans le cas de cette maison de luxe, il a d’abord fallu comprendre les processus opérationnels et les règles de gestion propres à chaque domaine: ventes, retail, digital, finance, supply chain, manufacturing ou encore produit.
Avant toute conception, nous nous sommes immergés dans le quotidien des métiers, jusqu’à en maîtriser les objets manipulés, les indicateurs clés et les logiques de pilotage.
Dans un univers où la rigueur des chiffres accompagne l’exigence créative, chaque indicateur a un sens : un chiffre de stock peut refléter un choix de rareté, une marge dépendre d’un positionnement produit, un taux de conversion exprimer la force d’un storytelling digital.
Cette connaissance fine permet de concevoir des produits data réellement utiles et de traduire fidèlement la réalité opérationnelle, tout en challengeant les besoins :
Pourquoi cet indicateur ? Quelle décision en découle ? Existe-t-il une donnée plus fiable ou plus pertinente ?
Ces échanges nourrissent une relation de partenariat durable avec les métiers, où la donnée devient un levier d’aide à la décision, et non une simple restitution.
Co-construction et conception des produits data
Une fois le besoin compris, vient la phase de cadrage et de conception, menée selon une méthodologie agile (SCRUM).
Chaque produit est le fruit d’une co-construction entre les métiers, les data analysts et les analytics engineers, suivant une logique produit plutôt que projet.
Les ateliers de cadrage explorent alors deux dimensions complémentaires :
- Fonctionnelle, centrée sur l’usage : pour quoi faire, par qui, avec quelle valeur ajoutée ?
- Technique, orientée faisabilité : quelles données sont disponibles, à quelle fréquence, avec quelles contraintes de performance et de coût ?
Cette double approche garantit un équilibre entre ambition métier et soutenabilité technique.
Ainsi, cette phase de conception inclue le maquettage collaboratif du produit permettant de définir les indicateurs à exposer, le niveau de granularité affiché et les filtres nécessaires. On procède également à des ateliers de validation visuel afin d’ajuster le rendu avant le développement.
Enfin, chaque livrable est conçu comme une brique fonctionnelle réutilisable et évolutive, selon une approche “produit”. Cette philosophie assure la pérennité, la maintenabilité et l’amélioration continue des développements, à mesure que les usages évoluent.
Data gouvernance, sponsorship et adoption
Tout au long du projet, la gouvernance data occupe une place centrale. D’autant plus dans ce contexte où cohabitent de multiples domaines : la cohérence des indicateurs et des référentiels est un enjeu clé.
Nous avons donc œuvré à uniformiser les règles de gestion et à établir des références communes par exemple :
- lorsqu’un indicateur commercial est défini par les équipes Sales, il devient la norme partagée ;
- lorsqu’un mapping produit ou une classification est issue du Merchandising, elle est adoptée par les autres domaines ;
Cette cohérence inter-domaines ne se décrète pas, elle se construit collectivement, en conciliant visions locales et globales et en accompagnant un véritable changement culturel.
Le succès repose aussi sur des sponsors métiers, figures clés dans chaque domaine, ils cadrent les besoins, arbitrent les priorités et portent les nouveaux usages auprès de leurs équipes.
En ancrant la donnée dans le quotidien des utilisateurs, ils ont permis une adoption naturelle et durable : la donnée devient alors un langage commun entre directions métiers, équipes de pilotage et analystes.
Chaque produit suit un cycle de vie agile, rythmé par le cadrage, le maquettage, le développement et les tests utilisateurs. Cette approche itérative favorise l’adaptation continue et des livraisons rapides.
Impliquant à la fois les métiers, les fonctions support et la direction, elle renforce la collaboration et aligne tous les acteurs autour d’une même vision de la donnée : fiable, performante et durable.
Approche technique et architecture de notre transformation data
Comment exploiter, révéler et structurer le potentiel de la Data Platform ?
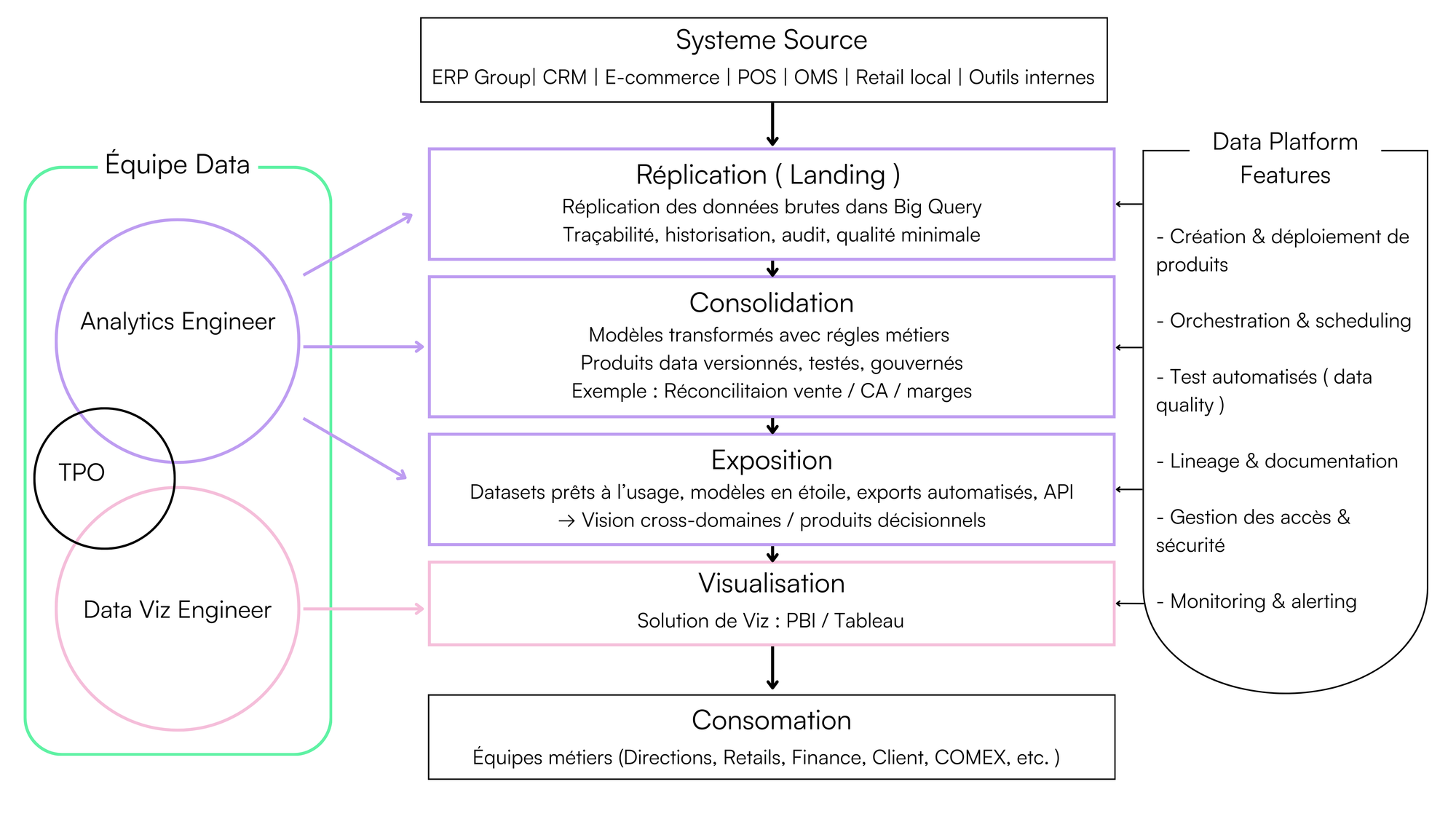
Lorsque nous avons rejoint cette maison de luxe, l’écosystème data reposait déjà sur la Data Platform du groupe, un socle technologique robuste intégrant :
- BigQuery comme entrepôt principal,
- dbt pour la modélisation et les tests,
- Airflow pour l’orchestration,
- et un environnement complet de CI/CD et monitoring.
Ce cadre technique mature offrait tout le nécessaire pour industrialiser la donnée, mais il n’était encore que partiellement exploité.
Notre mission a donc été de révéler son potentiel : concevoir et développer les produits data permettant d’en tirer une réelle valeur métier, tout en bâtissant une architecture scalable, modulaire et gouvernée.
Nous avons ainsi consolidé l’architecture en trois couches principales :
1- Landing – la donnée brute gouvernée : réplication data des systèmes sources du groupe, cette couche garantit la traçabilité complète avant toute transformation.
2- Consolidation – la transformation en produits data réutilisables : véritable cœur du lineage, chaque produit est une brique autonome définie par ses entrées, sorties, orchestration et tests contractuels.
Plus de 20 produits data ont été développés dont par exemple :
- la réconciliation des ventes et des ventes planifiées
- la modélisation comportementale client (récence, fréquence, panier, typologie),
- le rapprochement Retail/Digital pour une vision omnicanale,
- et l'agrégation de KPIs transverses (CA, volume, marge, taux de conversion, mix produits).
Ces produits centralisent les calculs complexes, garantissent la cohérence métier et simplifient le travail des équipes aval.
3- Exposition – la donnée est prête à l’usage : chaque produit alimente directement les utilisateurs à travers des datasets Power BI, des exports automatisés ou des solutions self-service. Les modèles sont construits selon les bonnes pratiques BI, garantissant robustesse, performance et fiabilité.
Modernisation, migration data et réduction des coûts
Une part essentielle du projet a aussi consisté à moderniser les flux existants et à migrer progressivement depuis le legacy vers la plateforme groupe.
Notre stratégie de migration depuis le legacy :
- Étape 1 : analyse et refactorisation du code historique,
- Étape 2 : shadow testing pour garantir la non-régression des KPIs critiques,
- Étape 3 : documentation et gouvernance des nouvelles sources répliquées.
Cette démarche a permis de supprimer les dépendances à des systèmes non maintenus et de fiabiliser les fondations.
Comment nous avons modernisé les pipelines :
- Étape 1 : amélioration des performances BigQuery (partitioning, clustering, caching),
- Étape 2 : refonte des transformations pour plus de réutilisabilité et de maintenabilité,
- Étape 3 : uniformisation des patterns et simplification des calculs.
Comment nous avons organisé l’optimisation continue et le monitoring :
Chaque produit est tagué par domaine pour un suivi précis des coûts et performances.
Les optimisations portent sur la matérialisation, les partitions temporelles, la revue régulière des requêtes et la surveillance des jobs coûteux.
Au global, cette démarche a permis de réduire les coûts, accélérer les temps d’exécution et renforcer la fiabilité des traitements.
Une transformation data fiable et documentée au service de la valeur
Pour garantir fiabilité et transparence pendant notre accompagnement dans la transformation data du client, nous avons mis en place un cadre reposant sur des standards d’assurance qualité. Nous avons construit un framework de data quality basé sur des macros dbt réutilisables, couvrant à la fois les tests techniques (fraîcheur, complétude, intégrité, formats) et fonctionnels (alignement Retail/Digital, concordance CA/volumes, validation des marges). Les résultats sont centralisés dans un dashboard de monitoring, avec alertes automatiques et blocage prévu de la propagation des modèles impactés.
Nous avons également documenté chaque produit de manière exhaustive, description fonctionnelle et technique, règles de gestion, mapping des KPIs, ownership et diagrammes de lineage synchronisée entre Confluence et dbt docs pour garantir accessibilité et traçabilité. Côté sécurité, nous avons mis en place une séparation stricte dev/prod, des déploiements via Git + CI/CD, une gestion fine des droits par dataset, du column masking et une conformité RGPD complète.
Enfin, nous avons instauré une culture “data as code” : conventions de nommage, linting SQL, standardisation dbt, revues systématiques, automatisation CI/CD et environnements de test. Au-delà des livrables, nous avons installé une manière commune de produire et collaborer, fondée sur la valeur métier, la fiabilité, la transparence et une ingénierie au service de la décision.
Impacts et résultats de notre accompagnement
Au terme de deux années d’accompagnement, la maison dispose désormais d’un écosystème data structuré, performant et adopté par les métiers. Les résultats observés traduisent à la fois la maturité technique atteinte et la capacité des équipes à s’approprier durablement les nouveaux usages. Ces avancées se traduisent par des résultats tangibles sur la performance et l’efficacité, tant sur le plan technique qu’organisationnel.
Fiabilité et performance data
La modernisation de l’architecture et des traitements a permis une réduction significative des coûts d’exécution BigQuery et des temps de traitement des pipelines, grâce à l’optimisation des requêtes, de la matérialisation et du partitionnement.
L’orchestration des flux a été adaptée à un mode event-driven, garantissant des données plus fraîches et exploitables au plus tôt.
Enfin, la mise en place d’un framework de data quality a permis de couvrir 25 % des modèles par des tests automatisés à la fin de l’accompagnement, renforçant la fiabilité de la plateforme.
Capitalisation et industrialisation de la donnée
Plus de vingt produits data et dix tableaux de bord métiers, dont deux à destination du COMEX, ont été livrés. Ces livrables, standardisés et mutualisés, ont contribué à un gain estimé d’environ dix ETP par semestre, notamment grâce à la réduction du retraitement manuel et à la fiabilisation des indicateurs. La création d’une base documentaire centralisée (Confluence et dbt docs) a, par ailleurs, réduit de moitié le temps d’onboarding des nouveaux membres de l’équipe data.
Une data gouvernance adoptée par les métiers
La démarche de gouvernance partagée a permis d’interconnecter huit domaines métiers autour d’indicateurs harmonisés.
Chaque domaine compte désormais environ soixante utilisateurs actifs mensuels sur les outils Power BI, témoignant d’une appropriation croissante par les équipes.
Cette cohérence repose sur l’implication de sponsors métiers formés et engagés, garants de la continuité et de la diffusion des bonnes pratiques.
La maison dispose aujourd’hui d’un socle data fiable, gouverné et orienté usage.
Les métiers accèdent à des indicateurs consolidés et partagés, facilitant un pilotage à la fois opérationnel et stratégique. Au-delà des résultats techniques, cette transformation a renforcé la collaboration entre les directions et installé une culture commune de la donnée centrée sur la fiabilité, la transparence et la valeur métier.








